Development of Machine-Learning Decision-Support Tools for Pavement Asset Management
This page details the methodology of a project (AAM6201) that is investigating ways artificial intelligence and machine learning can provide decision making support to managers of pavement assets. The project is being undertaken by WSP Australia, with input from a Project Working Group of Austroads member agency representatives. Qindong Li from Main Roads Western Australia is managing the project, which is due to be completed in late 2022.
Motivation
Pavement maintenance and renewal decision making are complex and heavily reliant on practitioner expertise and the corporate knowledge it embodies. It takes many years to develop this experience. Existing methods are always adapted to local conditions, and often incompletely documented or under-defined. Experts do not always agree, and justifications for complex multi-factor decisions are not always captured and maintained.
Managing pavement assets is an expensive, continual process. The quality of decision-making has a significant impact on budget and level of service provided. Staff turnover can therefore present significant difficulties for member authorities.
Can Machine Learning (ML) and Artificial Intelligence (AI) help agencies manage pavement assets? ML/AI research demonstrates great potential for improvement due to increasingly sophisticated methods and computational power. However, real-world experience shows that translating research into practice is difficult, with many ML/AI applications ending in failure. If we can explore some of the difficulties likely to be encountered in such applications, we can provide useful guidance and reduce risks for future projects.
Context
Machine Learning (ML) and Artificial Intelligence (AI) are already widely used in pavement asset management, albeit that use is limited to a few established use-cases. The most common use-cases are:
- Pavement condition forecasting or inference; deterioration model fitting
- Signal or image processing, for example, detection of cracks in video
- Optimisation of pavement maintenance programs, for example, to maximise levels of service given a specific annual budget.
This project aims to explore new use-cases for AI and/or ML, by providing decision-support to pavement asset managers. Decision-support means that rather than seeking to automate a process, we aim to develop software tools that help human experts make decisions, either by reducing the labour involved and/or providing additional insight to improve decisions and outcomes.
Using AI/ML in this guideline research we hope to help member authorities:
- capture and retain corporate knowledge
- reduce reliance on individual experts
- improve decision quality and consistency
- accelerate progress towards transparent, evidence-based processes
- understand and prepare for increasing quantities of data and consequential data management demands
- understand the implications of poor quality data on AI/ML adoption.
Case studies
This project is tackling these questions by addressing two specific use-cases:
- Case study A Project Identification: This task involves training ML models to capture and reproduce the treatment and project identification decisions of an experienced program developer.
- Case study B Funding Allocation: This task will develop a multi-criteria funding-allocation methodology that allows member authorities to make an informed judgement of suitable budget allocation splits and the implications of these decisions.
We anticipate that these case studies will explore some of the methodological and data-related issues likely to arise from the introduction of ML/AI in other pavement asset management use-cases.
The first task has been to train a ML model to reproduce the project identification decisions of an experienced asset manager, given typical pavement condition, traffic, and environmental inputs.
Projects are defined as the application of a treatment to multiple contiguous sections of road within a defined period of time. Our approach was to train the model to predict selected treatments for each road-section (typically approximately 100m), and then cluster individual section outcomes into projects.
Historic works programs data from NSW, NZ, VIC, and WA informed the ML models.
Target projects were defined as either forward-works programs (NSW, NZ and WA) or delivered-works programs (VIC). The primary difference between these is that delivered works programs are subject to additional contract management constraints, which were not captured in the input data, and are therefore harder for ML to reproduce.
To keep the complexity of the models manageable, the timing of treatment decisions was restricted to four windows:
- next year
- years 2-3
- years 4-5
- years 6-10.
Similarly, the model considers six broad classes of treatment options for which sufficient data was available:
- resurfacing spray seal (SS)
- resurfacing asphaltic concrete (AC)
- major patching
- retexturing
- rehabilitation
- regulation.
Therefore, for each road-section, the ML model is required to identify any appropriate combination of six treatments over the four time-periods using the input features provided.
Different input features were available in each dataset, but the most commonly available subset of features were:
- pavement age
- pavement type
- surface age
- surface material
- annual average daily traffic (AADT)
- heavy vehicles percentage
- roughness
- rutting.
Two types of ML models were developed to predict these treatments – Logistic Regression (LR) and XGBoost (XGB). LR has the advantage of being more interpretable, but is less powerful. XGB is more powerful and often a reasonable starting point for a new ML problem. However, it is more difficult to interpret the behaviour of XGB models.
The ML models were validated using statistical and qualitative approaches. For statistical validation, the accuracy, precision, recall and F1-Score of models were measured against validation sets not used during model training. (Since most road sections are not treated in any given year, there is a strong class imbalance towards no-treatment making high accuracy easy to achieve but misleading. Simply predicting “no treatment” will achieve accuracy of 90% or more.) Bootstrap resampling was used to explore the consistency of these performance metrics.
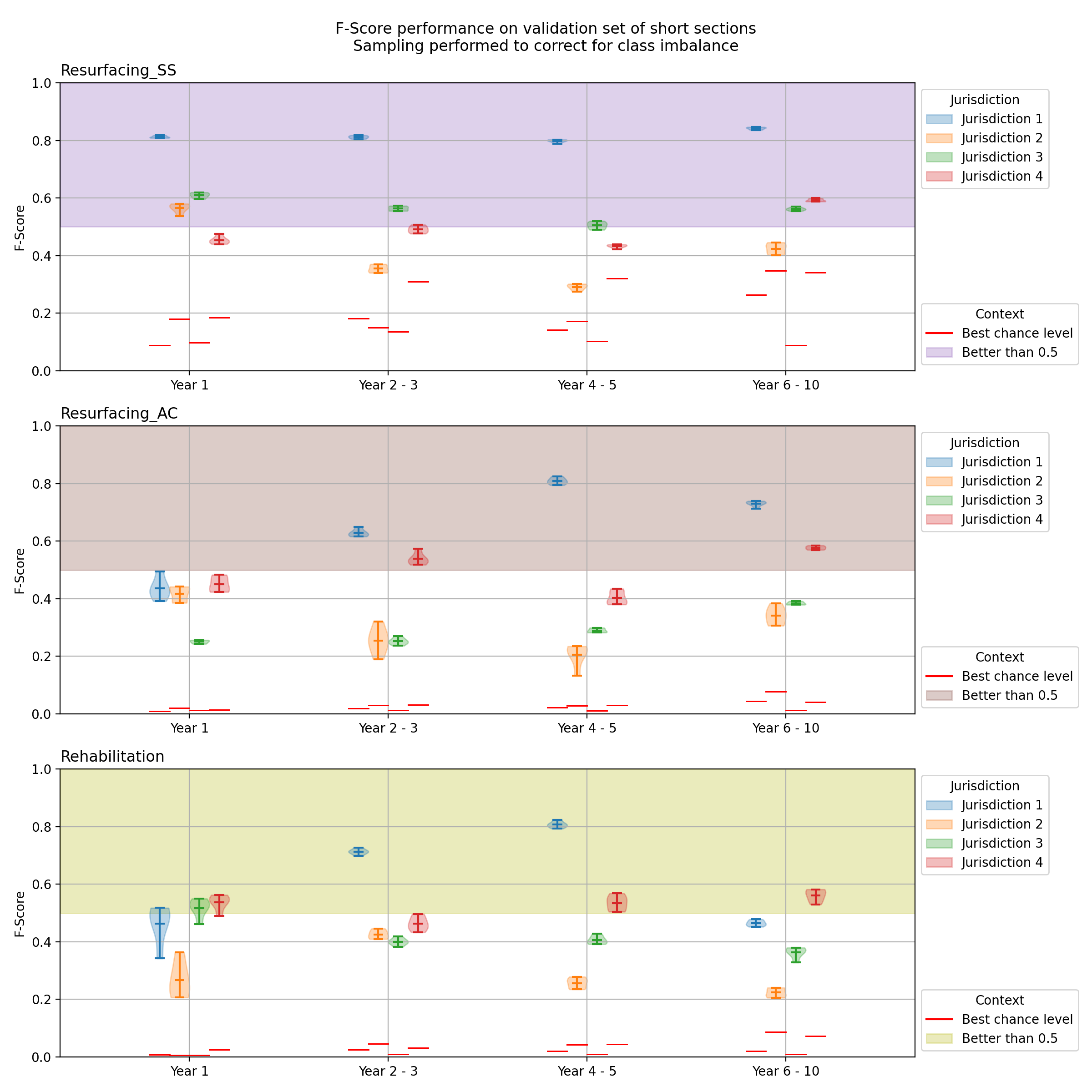
Caption: Preliminary results indicating performance of ML models when recommending whether to apply a specific treatment to each road section within a given window of time. The green shaded area represents an acceptable level of performance given typical inter-expert agreement. The coloured “violin” marks depict the range of performance observed in different samples from each agency dataset. Broadly, the ML models appear to predict treatments significantly better than chance level and with acceptable accuracy for most time-periods, treatment types and datasets, with some exceptions (Resurfacing AC (Asphalt) and Rehabilitation (particularly agency 2)).
Preliminary results suggest that ML models can learn to reproduce most expert decisions within a member authority to a comparable or slightly lesser degree than inter-expert agreement (F1-score 50-75%).

Caption: ML models generate recommendations for specific treatment of individual road sections at different time periods (bottom row). As an example, a length of a single lane road is displayed here. A clustering algorithm is applied to these recommendations to generate candidate projects of variable length (middle row). These candidate projects are then validated against projects from actual or planned works programmes (top row). In this instance, the model has broadly predicted two projects but incorrectly added a third, in which only a few sections may merit treatment.
The Project Working Group was keen to ensure that the ML models developed captured the expected interactions between input features and treatment decisions. To provide this confidence, the project team experts created a matrix of expected interactions. The team developed an objective methodology to classify whether the ML model considered each feature significant for each treatment option, and the direction of the relationship between input feature and treatment decision. Pleasingly, the human experts agreed with the vast majority of interactions identified by the ML model.
A transfer-learning task, in which ML models were trained on one member authority’s data, and then evaluated on another authority’s data was unsuccessful due to differences in:
- input feature availability
- input feature distribution
- treatment decision-making between all authorities.
However, this result is itself useful as it confirms the very different conditions and practices of member authorities.
Future development
Preliminary results appear to confirm we can train a model to capture and reproduce treatment decisions and timing. This technology could provide a tool to help practitioners better manage their networks by:
- Identifying differences between individual program developer’s recommendations and the standard agency model
- Providing a robust ML process to enable jurisdictions to validate evidence based treatment intervention triggers, embedded within Pavement Management Systems
- Providing an independent perspective when experts disagree or are unsure on the ideal treatment to select
- Evidence to support or refute inclusion of a specific treatment where the ideal action is ambiguous
- An independent source of recommendations to help provide a first cut" of a works program on new parts of the road network, or to assist less experienced asset managers
Beyond the current project, it may be possible to develop a more “universal” Australia-New Zealand pavement asset management “recommendation” tool which captures the range of practices used by member agencies and can adapt its recommendations to local conditions based on user feedback. This model would be conditional on a range of performance parameters provided by expert users.
The Project Working Group expressed a strong interest in a multi-factor funding-allocation problem as the desired use-case in Task B.
Many member authorities divide the network into smaller sub-networks which are funded through separate budget allocations. The two most commonly cited examples were:
- regional / metro split
- freight / non freight network split.
The multi-criteria funding allocation problem is technically difficult using current tools because funding allocations are an outcome of optimisation, not an input. To provide users with control over multi-criteria funding allocations, it is necessary to provide suitable penalties for each road-section based on status (e.g. freight route or regional road).
The relationship between penalties and funding allocation outcomes is nonlinear which makes it impractical to manually determine penalties. To counter this, the team developed an automated “meta-optimisation” algorithm to explore the penalty space and the impacts on funding allocations and levels of service.
The approach we are developing could easily be integrated into existing PMS optimisation workflows because most steps rely on existing software processes.
- First, we use the PMS to obtain an unconstrained set of treatments for the entire network.
- Second, we use the meta-optimisation algorithm to explore the funding allocation space and discover optimal service level outcomes for any funding allocation split. These results are presented graphically for discussion and to inform the final funding allocation split.
- Finally, we retrieve the correct penalty values to obtain the desired splits using conventional PMS optimisation of the entire network.

Caption: The effect of different multi-criteria funding allocation scenarios on overall network level of service (LoS). Two criteria are explored here: Metro/regional split, and freight/non-freight split. Via a meta-search algorithm, each dot represents the optimal level of service achieved given a particular allocation split between metro/regional and freight/non-freight routes. Dots are colour coded by budget utilisation – some splits cannot utilise all the available budget. The Z-axis shows level of service, so higher dots represent better service levels. The red plane is the service level achieved by the current funding split; notably, higher service levels are achievable. The results show that LoS is less sensitive to freight sub-network expenditure than metro / regional split.
Future development
We believe that the funding allocation modelling work has relevance to several member agencies and we hope to be able to work with one or more agencies to adopt this methodology.
Reports
In December 2022 Austroads published Development of Machine-Learning Decision Support Tools for Pavement Asset Management. The report details the research and is accompanied by a quick reference containing a set of practical resources to help define and scope AI/ML projects.
What’s coming?
Join us for two webinars in February 2023 with authors Tim Cross and David Rawlinson.
Success Strategies for Delivering Artificial Intelligence and Machine Learning Projects
Tuesday, 21 February 2023
This session will describe tips, tricks and success strategies to ensure AI/ML projects proceed to delivery and successful integration with existing business processes. We will work through the Quick Reference and explain how to use these tools with practical examples.
Development of Machine Learning Decision Support Tools for Pavement Asset Management
Friday, 24 February 2023
This session will describe two case studies in the use of machine learning (ML) and artificial intelligence (AI) to create decision-support tools for pavement asset management. In the first study, we explore whether ML can learn to reproduce expert treatment decisions and automatically identify candidate projects, using historic condition, treatment and inventory data. In the second, we explore extensions to conventional Pavement Management System (PMS) optimisation tools which provide insight into the network-wide implications of various multi-criteria funding allocation scenarios, and the levels of service that can potentially be realised.
No charge but registration is essential.
Can’t make the live sessions? Register and we’ll send you a link to the recording.
Updated: December 2022.